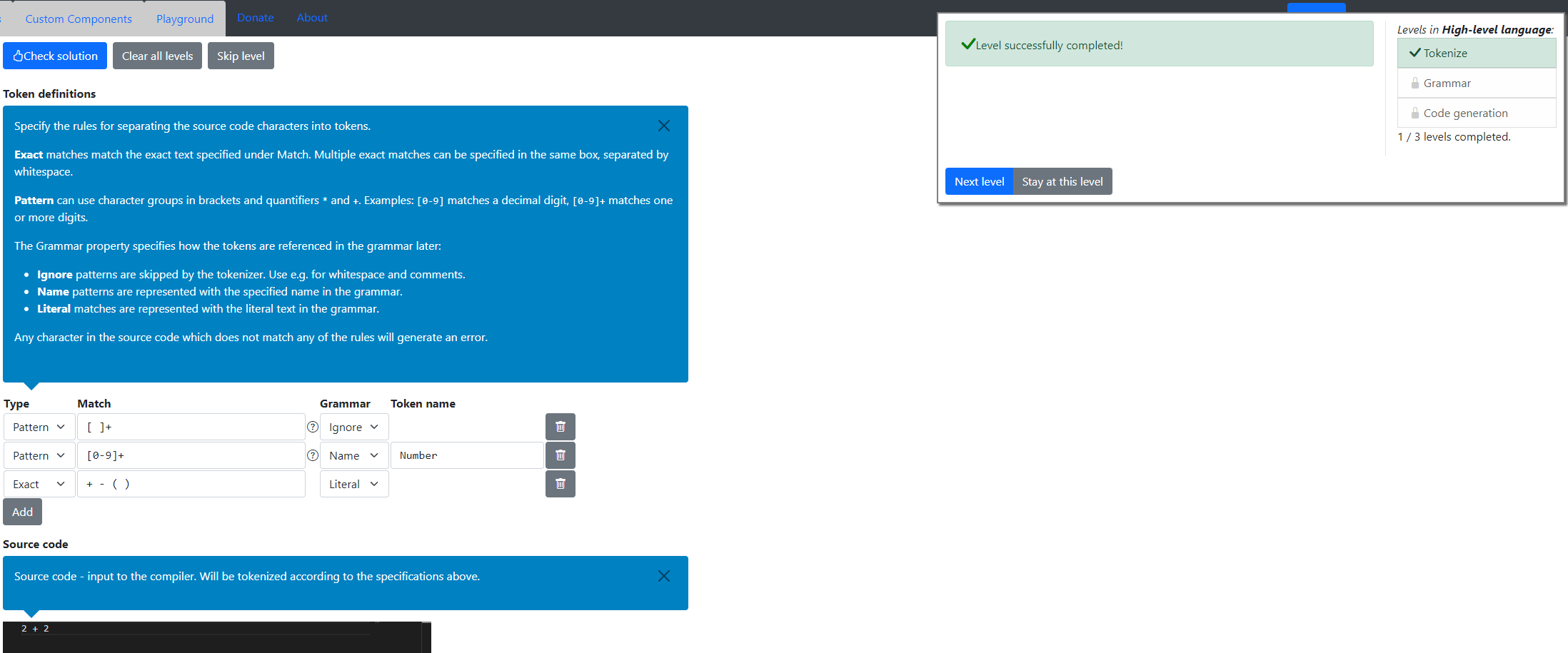
Tokenize【NandGame編】
目次
はじめに
いつもブログをご覧いただきありがとうございます。
ミジンコに転生したIPUSIRONです😀
コンパイルするということ
高級言語はアセンブリー言語より人間にやさしく柔軟な構文を持ちます。コンピューターは高級言語のコードを貴秋後コード命令にコンパイルすることで、最終的にCPUが解釈できるようになります。
例えば、2+2という高級言語のコードがあった場合、コンパイルすると次のコードになります。ただし、PUSH_VALUE、ADDはマクロです。
PUSH_VALUE 2
PUSH_VALUE 2
ADDコンパイルには次に示す3段階があります。
①トークン化(Tokenize)・・・テキストを数字・キーワード・記号を表す単位(トークンという)に分割する。
②構文解析(Parsing)
③コード生成(Code generation)
Tokenizeレベル
Tokenizeレベルのゴールは、数字、記号「+」「-」「(」「)」のトークン化を実現することです。Token definitionsにルールを設定します。

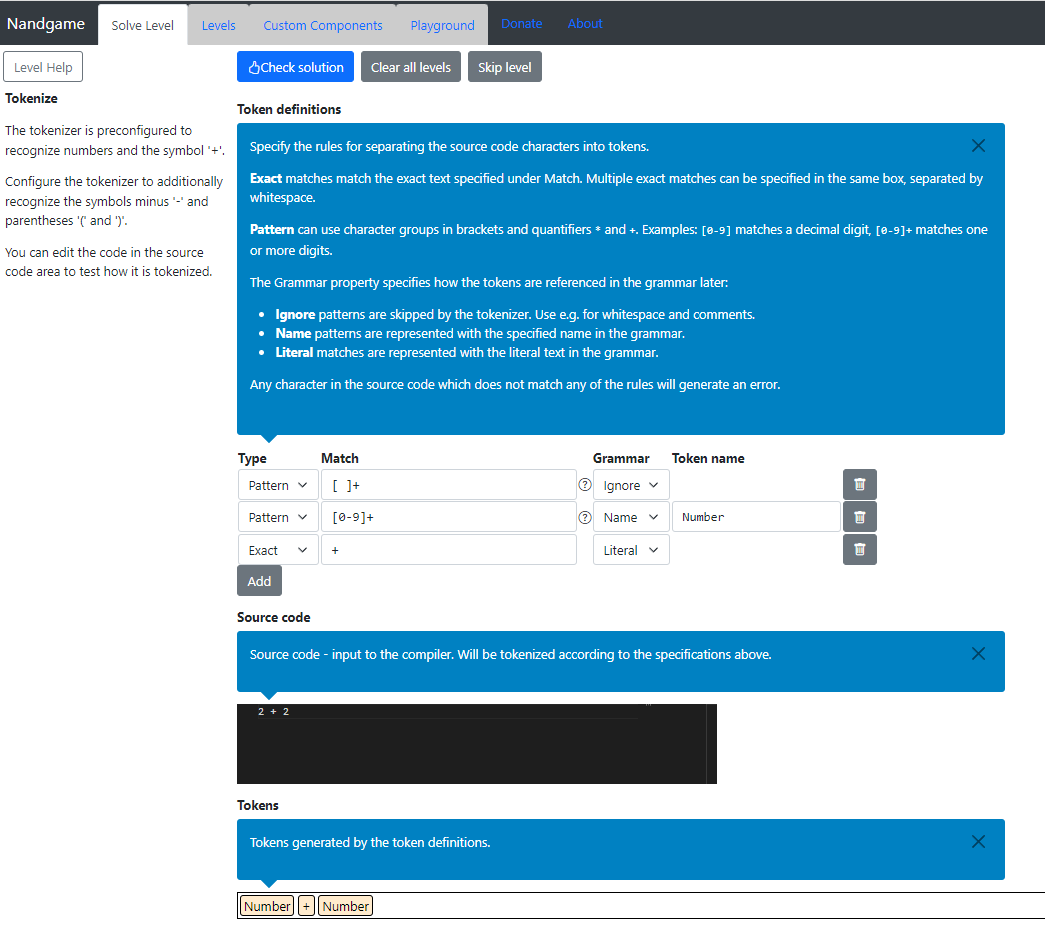
Tokenizeレベルの画面説明
画面中央は、次の3つに分けられます。
- Token definitionsエリア・・・ソースコードの文字をトークン化するルールを設定する。
- Source codeエリア・・・ソースコードを入力できる。
- Tokensエリア・・・トークン化した結果。
Token definitionsエリア
Typeプロパティ
Typeのプルダウンで次のどちらかを指定します。
- Exact・・・完全一致のルール。複数の完全一致を同一テキストボックス内に空白区切りで指定できる。
- Pattern・・・パターンでマッチしたときのルール。Matchプロパティには
Matchプロパティ
Matchのテキストボックスに入力します。
文字のグループをブラケット、*、+で表現できます
例えば、[0-9]は1桁の10進数値に、[0-9]+は任意の桁の10進数値にマッチします。
Grammarプロパティ
トークンがどのように参照されるかを選びます。Grammarのプルダウンで次の3つのいずれかを指定できます。
- Ignore・・・無視する。空白とコメント用。
- Name・・・トークン名(Token name)で指定した名前。
- Literal・・・リテラルテキスト。
Source codeエリア
画面中央の”Source code”エリアでコードを編集して、トークン化のテストができます。
ソースコード内にどのルールにも一致しない文字があると、エラーが発生します。

Tokensエリア
デフォルトでは次の3つのルールが設定されています。
- 「[ ]+」パターンにマッチしたらIngore。つまり、空白列は無視。
- 「[0-9]+」パターンは、トークン名"Number"に置き換え。
- 「+」に完全一致、すなわちプラス記号はそのままリテラルテキストとして出力する。
最初の例として、Source codeエリアに「2 + 2」がありますが、上記の3つのルールにより、「Number」「+」「Number」という3トークンに処理されます。
Tokenizeレベルを解く
Token Definitionsにルールを追加して、数字、記号「+」「-」「(」「)」をトークン化させます。
数字のトークン化については、2番目のデフォルトルールで満たしています。
記号「+」のトークン化については、3番目のデフォルトルールで満たしています。
この3番目のルールと同様にして、残りの記号もリテラルテキストとすればよいわけです。
1つずつ追加してもよいですが、空白区切りで複数設定できると説明されています。そこで、次のようにします。
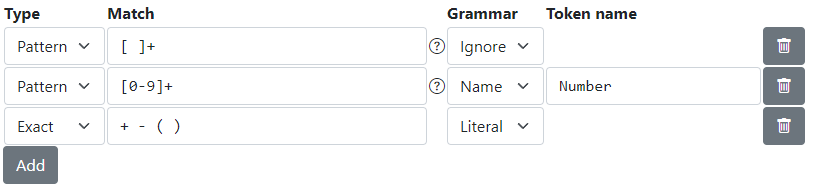
これでTokenizeレベルはクリアになります。