MONOALPHABETIC SUBSTITUTION PUZZLE 02【Cypher編】
はじめに
いつもブログをご覧いただきありがとうございます。
ミジンコに転生したIPUSIRONです😀
暗号文

LGGK VHZXJ RP VJJCEVO CK ZMX MGEXO C SCLDGEXJXS
LGRX IVIXJL CK ZMX IGDQXZ GH ZMX SJXLL UMCDM C MVS
ZVQXK HJGR PGBJ OVWGJVZGJP. VZ HCJLZ C MVS
KXNOXDZXS ZMXR, WBZ KGU ZMVZ C UVL VWOX ZG SXDCIMXJ
ZMX DMVJVDZXJL CK UMCDM ZMXP UXJX UJCZZXK, C
WXNVK ZG LZBSP ZMXR UCZM SCOCNXKDX.
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| 00 | 03 | 18 | 09 | 03 | 00 | 14 | 04 | 04 | 16 | 10 | 10 | 18 | 03 | 06 | 05 | 02 | 05 | 09 | 00 | 07 | 16 | 04 | 29 | 00 | 24 |
ヒント
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
The most common English trigram is "the".
解答への道
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
1:解読方針を考察する
単一換字式暗号の暗号文であることはわかっています。
太字の暗号文単語"OVWGJVZGJP"を特定するのが目標になります。
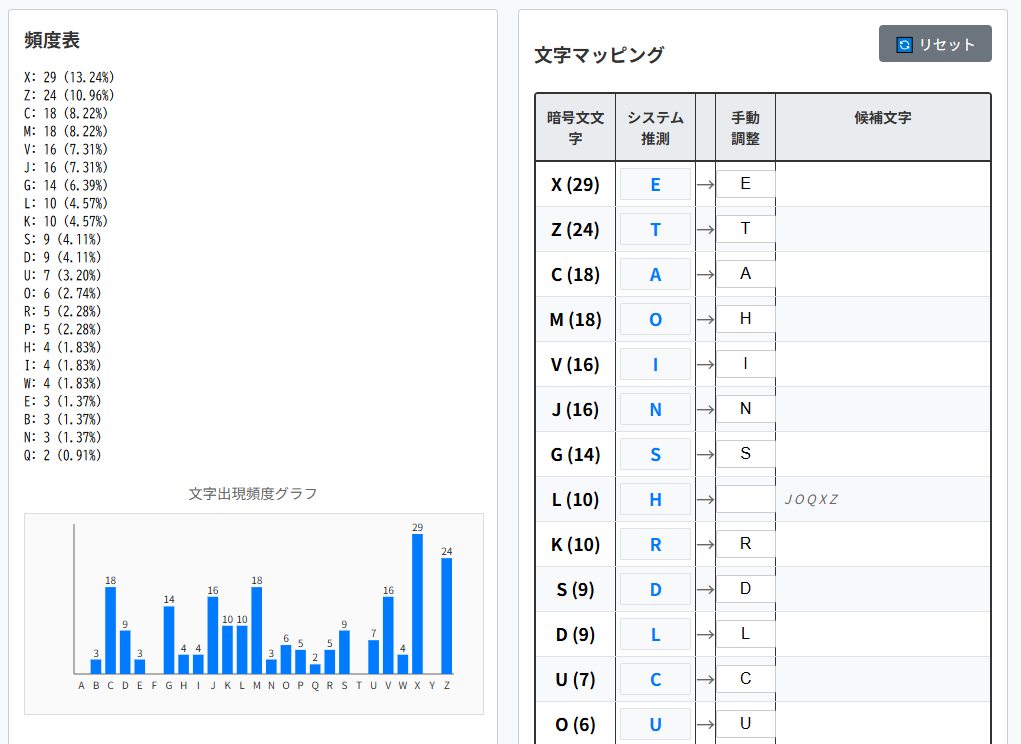
PUZZLE 01では、置換表(暗号文文字と平文文字の対応)の一部が与えられていましたが、今回はまったく与えられていません。代わりに暗号文の頻度表(アルファベットとその登場回数の一覧表)が与えられています。
暗号文の下にある表は、頻度表です。
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| 0 | 3 | 18 | 9 | 3 | 0 | 14 | 4 | 4 | 16 | 10 | 10 | 18 | 3 | 6 | 5 | 2 | 5 | 9 | 0 | 7 | 16 | 4 | 29 | 0 | 24 |
暗号文メッセージには空白区切りがあるので、単語の切れ目がわかります。
2:1文字単語を利用する
英文には1文字単語として、’a’と’i’(英文では大文字の’I’)しかありません。
今回の暗号文メッセージには、’C’という1文字の暗号文単語が4回出現しています。他に1文字の暗号文単語はありません。
暗号文文字’C’が平文文字’a’か’i’に対応します。古い文章では、文の途中でも’I’が単独で使われる可能性があるため、’a’であると断定できません。
※確定していないので太字にしています。
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| a i |
3:"the"を特定する
“the"と特定することは単一換字式暗号の暗号解読で有効な手法です。
次の理由が挙げられます。
- 最頻文字の’e’や’t’を含む。
- “the"そのものが頻出のトリグラフである。
- “they"、"there"、"then"、"these"、"their"などの単語に含まれる。
以上より、"the"の特定に力を注ぐことにします。
頻度表を見ると最頻の文字は’X’です。しかも29回と、他の文字に比べて極端に出現回数が多いです。一方、英文の最頻文字は’e’です。
よって、暗号文文字’X’は平文文字’e’に対応する可能性が高いといえます。
さらに、解読を進めます。
英文の最頻の3連字(=トリグラフ=トリグラム)は"the"であるというヒントが与えられています。
直前でちょうど’e’を推測したので、"the"の特定は都合がよいといえます。
暗号文メッセージから3連字を抽出し、"??e"("??X")と合致するものを探すと、1つだけあります。
それが"ZMe"("ZMX")です。4回も出現していることからも、最頻単語の1つである事実にも符合しています。
芋づる式に、暗号文文字’Z’は平文文字’t"、暗号文文字’M’は平文文字’h"であることを推測できます。
暗号文文字’Z’は24回出現しており、この暗号文メッセージでは2番目の頻度です。一方、英文では2番目の頻出文字が’t’である事実とも符合しており、"the"の推測はほぼ間違いないといえます。
以上を置換表にまとめておきます。
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| a i | h | e | t |
LGGK VHteJ RP VJJCEVO CK the hGEeO C SCLDGEeJeS
LGRe IVIeJL CK the IGDQet GH the SJeLL UhCDh C hVS
tVQeK HJGR PGBJ OVWGJVtGJP. Vt HCJLt C hVS
KeNOeDteS theR, WBt KGU thVt C UVL VWOe tG SeDCIheJ
the DhVJVDteJL CK UhCDh theP UeJe UJCtteK, C
WeNVK tG LtBSP theR UCth SCOCNeKDe.4:’i’を確定する
ここからは少し解読が難しくなってきます。
再度頻度表を参照してください。
頻度の高い暗号文文字がまだ残っているので、これらの解読を進めてみます。
ここで頻度表と置換表をマージしておきます。
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| 0 | 3 | 18 | 9 | 3 | 0 | 14 | 4 | 4 | 16 | 10 | 10 | 18 | 3 | 6 | 5 | 2 | 5 | 9 | 0 | 7 | 16 | 4 | 29 | 0 | 24 |
| a i | h | e | t |
4行目の5文字目の単語"thVt"に注目してください。
暗号文文字’V’には自然と’a’が当てはまります。
よって、暗号文文字’C’は消去法的に平文文字’i’に対応します。
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| 0 | 3 | 18 | 9 | 3 | 0 | 14 | 4 | 4 | 16 | 10 | 10 | 18 | 3 | 6 | 5 | 2 | 5 | 9 | 0 | 7 | 16 | 4 | 29 | 0 | 24 |
| i | h | a | e | t |
LGGK aHteJ RP aJJiEaO iK the hGEeO i SiLDGEeJeS
LGRe IaIeJL iK the IGDQet GH the SJeLL UhiDh i haS
taQeK HJGR PGBJ OaWGJatGJP. at HiJLt i haS
KeNOeDteS theR, WBt KGU that i UaL aWOe tG SeDiIheJ
the DhaJaDteJL iK UhiDh theP UeJe UJitteK, i
WeNaK tG LtBSP theR Uith SiOiNeKDe.もし最初に暗号文文字’C’が平文文字’a’に対応すると誤った推測をした場合、以降どこかで破綻します。
破綻すること自体はよいのです。そして、破綻を恐れてはいけません。
暗号解読において、こういうことはよくあるのです。
そういった場面に出会ったら、落ち着いて前の手順に戻りましょう。
場合によっては解読をやり直した方が早いときさえあります。
複写した書き起こし(トランスクリプト)が間違えている可能性も疑いましょう。
5:最頻文字を攻める
単一換字式暗号のステージに、英文におけるアルファベットの頻度の割合がヒントとして描かれています。

最頻文字を並べた文字列"ETOAN"のうち、’e’、’t’、’a’の特定を終えています。残りは’o’と’n’になります。
暗号文文字’G’、’J’の頻度が高いため、どれらかが’o’や’n’に対応すると考えられます。
暗号文文字’J’はたくさん登場していますが、長めの単語に埋め込まれているので、まだ攻めにくそうです。
4行目の後ろから3番目の単語"tG"という2連字は、攻めやすそうです。
子音だけで構成される2連字はほとんど考えられません。よって、消去法で、暗号文文字’G’が平文文字’o’に対応するはずです。
1行目の1番目の単語”LGGK"は1223型です。1223型の単語として、"book"、"food"、"soon"、"been"、"feed"、"feet"、"seek"などがあります。
2の平文文字は’e’か’o’になります。すでに’e’は使っているので、残された’o’の可能性が高いです。このことからも暗号文文字’G’が平文文字’o’に対応することを裏づけられます。
よって、暗号文文字’G’が平文文字’o’に対応するのはほぼ確定です。
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| 0 | 3 | 18 | 9 | 3 | 0 | 14 | 4 | 4 | 16 | 10 | 10 | 18 | 3 | 6 | 5 | 2 | 5 | 9 | 0 | 7 | 16 | 4 | 29 | 0 | 24 |
| i | o | h | a | e | t |
LooK aHteJ RP aJJiEaO iK the hoEeO i SiLDoEeJeS
LoRe IaIeJL iK the IoDQet oH the SJeLL UhiDh i haS
taQeK HJoR PoBJ OaWoJatoJP. at HiJLt i haS
KeNOeDteS theR, WBt KoU that i UaL aWOe to SeDiIheJ
the DhaJaDteJL iK UhiDh theP UeJe UJitteK, i
WeNaK to LtBSP theR Uith SiOiNeKDe.消去法的に暗号文文字’J’を平文文字’n’にしたいところですが、まだ確認を持てません。
次はその対応を適用した場合のメッセージです。
LooK aHten RP anniEaO iK the hoEeO i SiLDoEeneS
LoRe IaIenL iK the IoDQet oH the SneLL UhiDh i haS
taQeK HnoR PoBn OaWonatonP. at HinLt i haS
KeNOeDteS theR, WBt KoU that i UaL aWOe to SeDiIhen
the DhanaDtenL iK UhiDh theP Uene UnitteK, i
WeNaK to LtBSP theR Uith SiOiNeKDe.いくつか怪しい単語があります。"aHten"、"anniEaO"、"Uene"などです。
よって、まだこの対応は適用しないことにします。
6:"the"の隣接文字に注目する
一度攻める方向を変えてみます。
すでに"the"を特定しているので、その隣接文字が攻める候補となります。
“theR"、"theP"に注目します。
1行目の3番目に2連字"RP"があるので、特定しやすいそうです。
“them"、"they"、"then"が考えられますが、2連字"RP"を考慮すると、"RP"は"my"に対応すると推測できます。
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| 0 | 3 | 18 | 9 | 3 | 0 | 14 | 4 | 4 | 16 | 10 | 10 | 18 | 3 | 6 | 5 | 2 | 5 | 9 | 0 | 7 | 16 | 4 | 29 | 0 | 24 |
| i | o | n? | h | y | m | a | e | t |
LooK aHteJ my aJJiEaO iK the hoEeO i SiLDoEeJeS
Lome IaIeJL iK the IoDQet oH the SJeLL UhiDh i haS
taQeK HJom yoBJ OaWoJatoJy. at HiJLt i haS
KeNOeDteS them, WBt KoU that i UaL aWOe to SeDiIheJ
the DhaJaDteJL iK UhiDh they UeJe UJitteK, i
WeNaK to LtBSy them Uith SiOiNeKDe.かなりよい感じです。
暗号解読でうまくいく場合にはすいすいいくものです。
7:連字を攻める
“iK"が3回も登場しています。
候補となる平文単語は"in"、"it"、"is"です。
つまり、暗号文文字’K’は、平文文字’n’、’t’、’s’に対応する可能性があります。ただし、’t’はすでに使用済みです。もっとも可能性が高いのは’n’です。
次に、未解読の別の連字を探します。
“oH"がありました。
候補となる平文単語は"on"、"or"、"of"です。
つまり、暗号文文字’H’は、平文文字’n’、’r’、’f’に対応する可能性があります。
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| 0 | 3 | 18 | 9 | 3 | 0 | 14 | 4 | 4 | 16 | 10 | 10 | 18 | 3 | 6 | 5 | 2 | 5 | 9 | 0 | 7 | 16 | 4 | 29 | 0 | 24 |
| i | o | n r f | n? | n s | h | y | m | a | e | t |
そろそろだ大胆な推測が必要になります。
・暗号文文字’K’が平文文字’n’に対応すると、"LooK"⇒"Loon"となる。"moon"、"soon"が考えられる。
・暗号文文字’K’が平文文字’s’に対応すると、"LooK"⇒"Loos"となり、不自然。
・暗号文文字’H’が平文文字’n’に対応すると、"aHteJ"⇒"anteJ"となり、不自然。’K’が’n’に対応したとすれば、そもそも使えない。
・暗号文文字’H’が平文文字’r’に対応すると、"aHteJ"⇒"arteJ"となる。"arter"ならありえるが、そうなっていない。
・暗号文文字’H’が平文文字’f’に対応すると、"aHteJ"⇒"afteJ"となる。すぐに"after"が思いつく。暗号文文字’J’は最頻、かつ’r’はETOANIに次ぐ頻度であることに矛盾しない。
以上から、暗号文文字’K’が平文文字’n’、暗号文文字’H’が平文文字’f’、暗号文文字’J’が平文文字’r’に対応すると推測します。
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| 0 | 3 | 18 | 9 | 3 | 0 | 14 | 4 | 4 | 16 | 10 | 10 | 18 | 3 | 6 | 5 | 2 | 5 | 9 | 0 | 7 | 16 | 4 | 29 | 0 | 24 |
| i | o | f | r | n | h | y | m | a | e | t |
Loon after my arriEaO in the hoEeO i SiLDoEereS
Lome IaIerL in the IoDQet of the SreLL UhiDh i haS
taQen from yoBr OaWoratory. at firLt i haS
neNOeDteS them, WBt noU that i UaL aWOe to SeDiIher
the DharaDterL in UhiDh they Uere Uritten, i
WeNan to LtBSy them Uith SiOiNenDe.8:単語を類推する
・"firLt"は"first"⇒暗号文文字’L’は平文文字’s’に対応する。
・"yoBr"は"your"⇒暗号文文字’B’は平文文字’u’に対応する。
・"haS"は"has"または"had"⇒上記の推測で’s’は使えない。さらに、暗号文文字と平文文字が同じというのは少し考えにくい⇒暗号文文字’S’は平文文字’d’に対応する。
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| 0 | 3 | 18 | 9 | 3 | 0 | 14 | 4 | 4 | 16 | 10 | 10 | 18 | 3 | 6 | 5 | 2 | 5 | 9 | 0 | 7 | 16 | 4 | 29 | 0 | 24 |
| u | i | o | f | r | n | s | h | y | m | d | a | e | t |
soon after my arriEaO in the hoEeO i disDoEered
some IaIers in the IoDQet of the dress UhiDh i had
taQen from your OaWoratory. at first i had
neNOeDted them, Wut noU that i Uas aWOe to deDiIher
the DharaDters in UhiDh they Uere Uritten, i
WeNan to study them Uith diOiNenDe.さらに類推を継続します。
・"Uith"は"with"、"Uritten"は"writtern"、"Uere"は"wrere"⇒暗号文文字’U’は平文文字’w’に対応する。
・"arriEaO"は"arrival"⇒暗号文文字’E’は平文文字’v’、暗号文文字’O’は平文文字’l’に対応する。
・"Wut"は"but"⇒暗号文文字’W’は平文文字’b’に対応する。
・"disDovered"は"discovered"⇒暗号文文字’D’は平文文字’c’に対応する。
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
| 0 | 3 | 18 | 9 | 3 | 0 | 14 | 4 | 4 | 16 | 10 | 10 | 18 | 3 | 6 | 5 | 2 | 5 | 9 | 0 | 7 | 16 | 4 | 29 | 0 | 24 |
| u | i | c | v | o | f | r | n | s | h | l | y | m | d | w | a | b | e | t |
soon after my arrival in the hovel i discovered
some IaIers in the IocQet of the dress which i had
taQen from your laboratory. at first i had
neNlected them, but now that i was able to deciIher
the characters in which they were written, i
beNan to study them with diliNence.9:特定すべき暗号文単語"OVWGJVZGJP"が解読できた
対応する平文単語は"laboratory"になります。
解答
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
↓↓下にスクロール↓↓
LABORATORY
メッセージは何だったのか
部分的に解読できたメッセージは次のようになります。
soon after my arrival in the hovel i discovered
some IaIers in the IocQet of the dress which i had
taQen from your laboratory. at first i had
neNlected them, but now that i was able to deciIher
the characters in which they were written, i
beNan to study them with diliNence.文頭や’i’を大文字にして、英文らしくしましょう。
Soon after my arrival in the hovel I discovered
some IaIers in the IocQet of the dress which I had
taQen from your laboratory. At first I had
neNlected them, but now that I was able to deciIher
the characters in which they were written, I
beNan to study them with diliNence.“Soon after my arrival in the hovel I discovered"でGoogle検索します。
すると、小説"Frankenstein"の一節であることがわかります。
Soon after my arrival in the hovel I discovered some papers in the pocket of the dress which I had taken from your laboratory. At first I had neglected them, but now that I was able to decipher the characters in which they were written, I began to study them with diligence.

ツールで解読する
1:頻度分析が有効なので、Frequency Analyzerで解読します。

ブラウザーで開いてください。
2:入力欄に暗号文を入力して、[頻度分析]ボタンを押します。
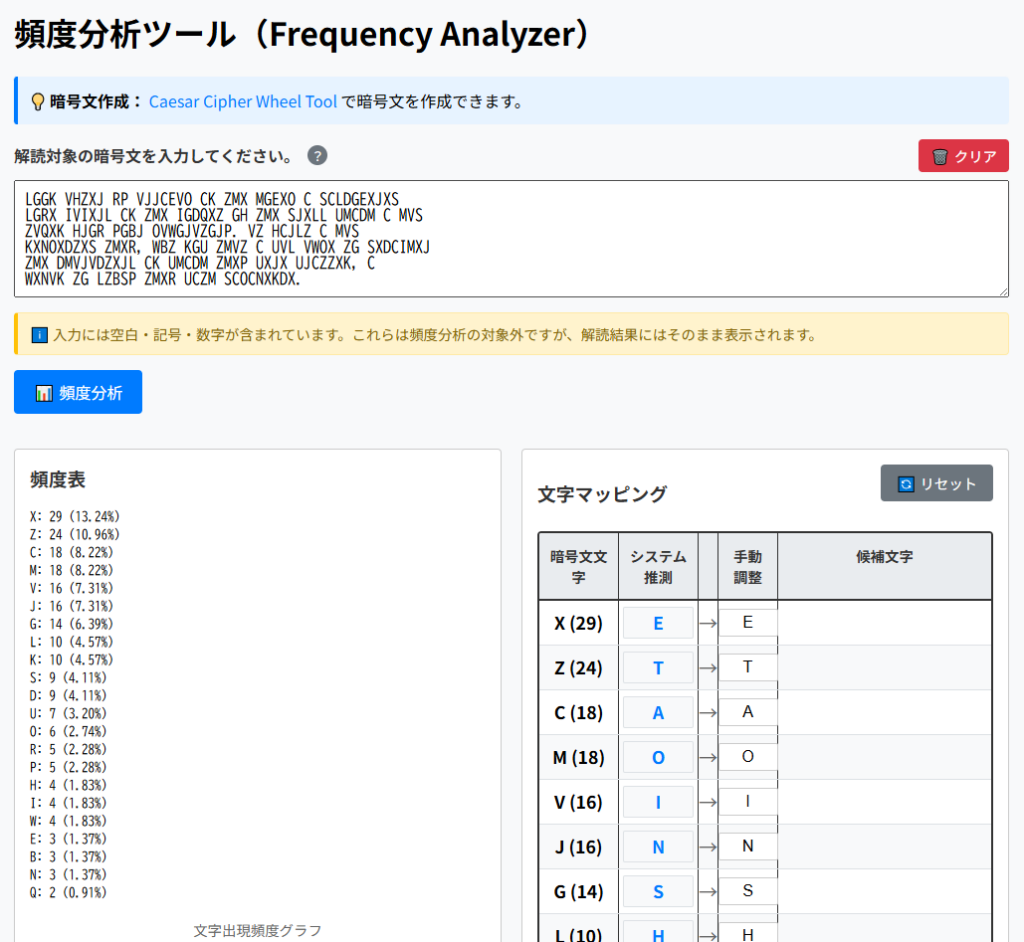
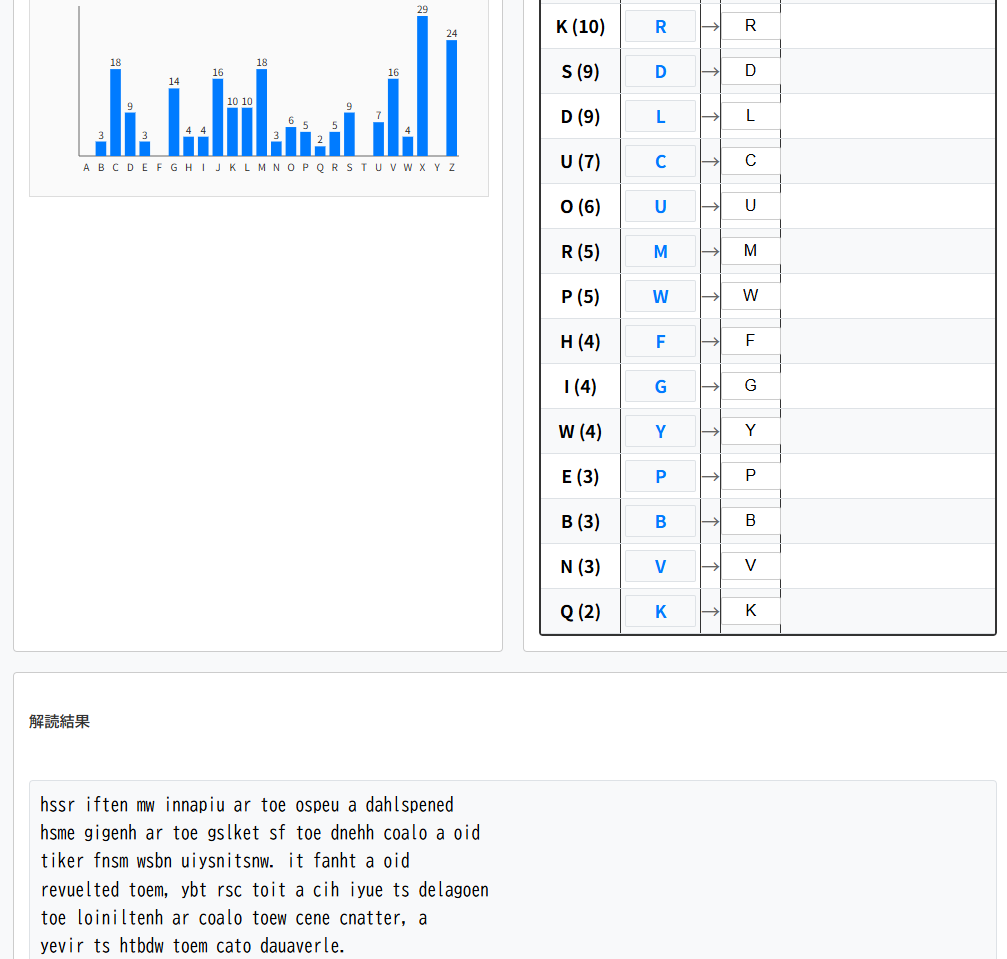
hssr iften mw innapiu ar toe ospeu a dahlspened
hsme gigenh ar toe gslket sf toe dnehh coalo a oid
tiker fnsm wsbn uiysnitsnw. it fanht a oid
revuelted toem, ybt rsc toit a cih iyue ts delagoen
toe loiniltenh ar coalo toew cene cnatter, a
yevir ts htbdw toem cato dauaverle.
単純な解読結果では、まだ英文として成り立っていません。
そこで手動での解読に切り替えます。
2:今回の暗号文には空白があり、単語の区切りがわかります。
そのため頻出単語をヒントとして解読を進められます。
暗号文には"ZMX"という3文字が目立ちます。

これは英語の"the"に対応している可能性がとても高いといえます。
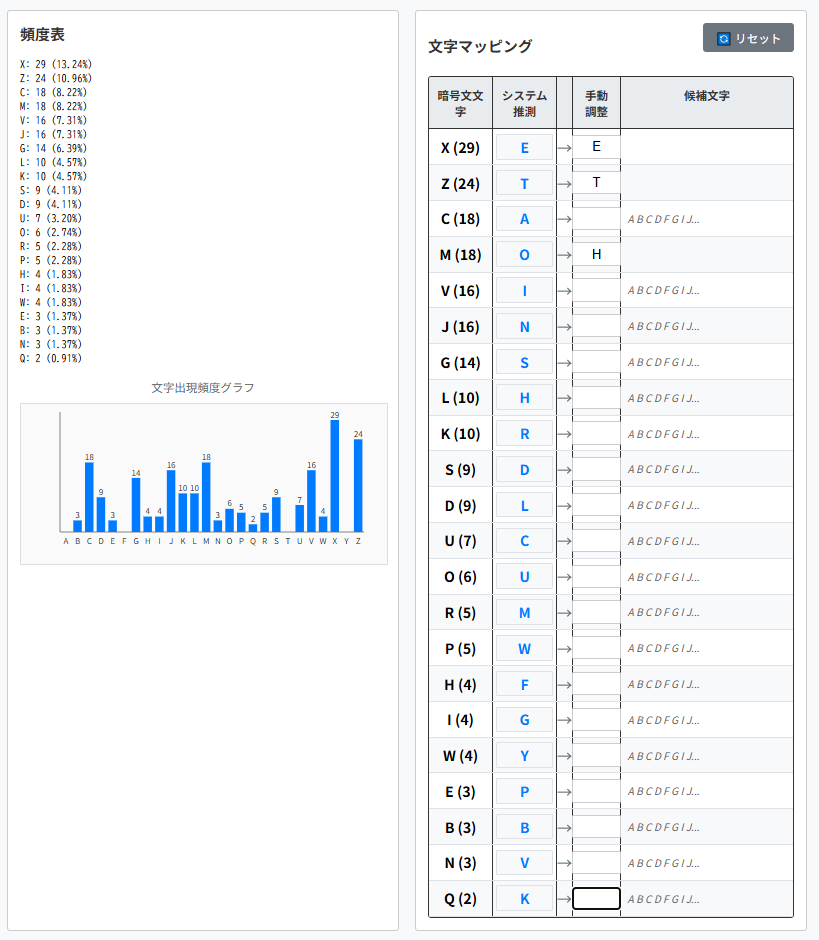
ツールの解析結果では"ZMX"⇒"toe"となっていましたが、’M’の解読が間違っていただけと判断できます。
ツールの文字マッピングにおいて、暗号文文字’M’⇒平文文字’h’に修正しておきます。
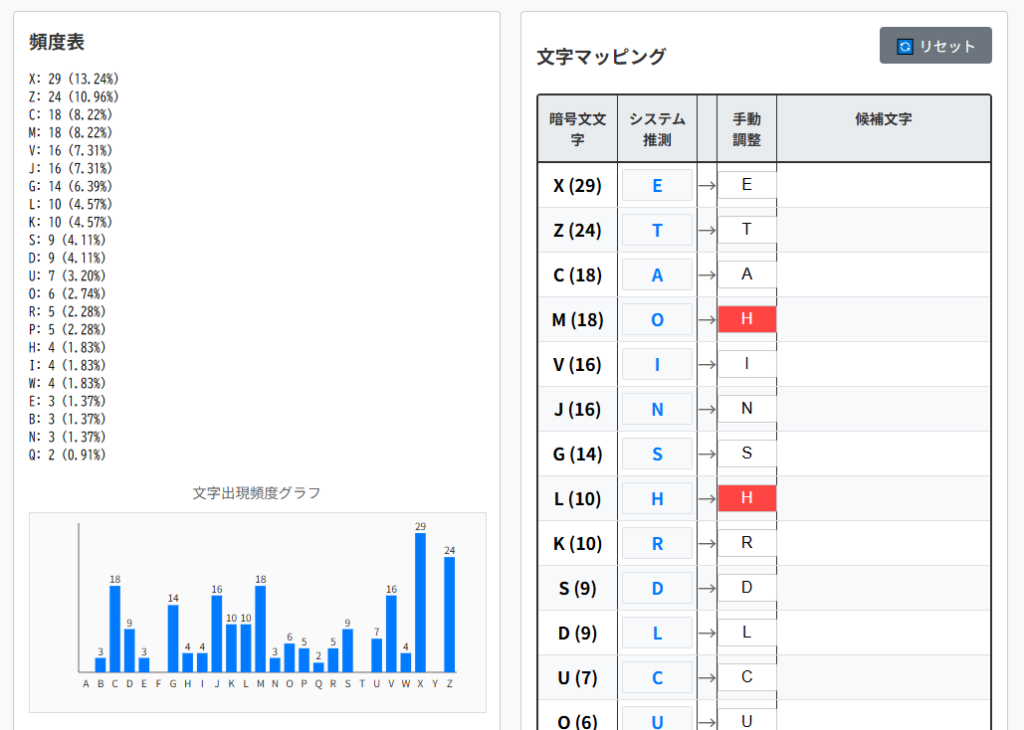
平文文字’h’が他のマッピングと重複してしまっていますので、そこを空指定しておきます。
Lssr iften mw innapiu ar the hspeu a daLlspened
Lsme gigenL ar the gslket sf the dneLL chalh a hid
tiker fnsm wsbn uiysnitsnw. it fanLt a hid
revuelted them, ybt rsc thit a ciL iyue ts delaghen
the lhiniltenL ar chalh thew cene cnatter, a
yevir ts Ltbdw them cath dauaverle.
一部の単語は英語らしくなってきましたが、全体的にはまだ英文になっていません。
解くべきキーワードも"uiysnitsnw"のままであり、正解とはほぼ遠いです。
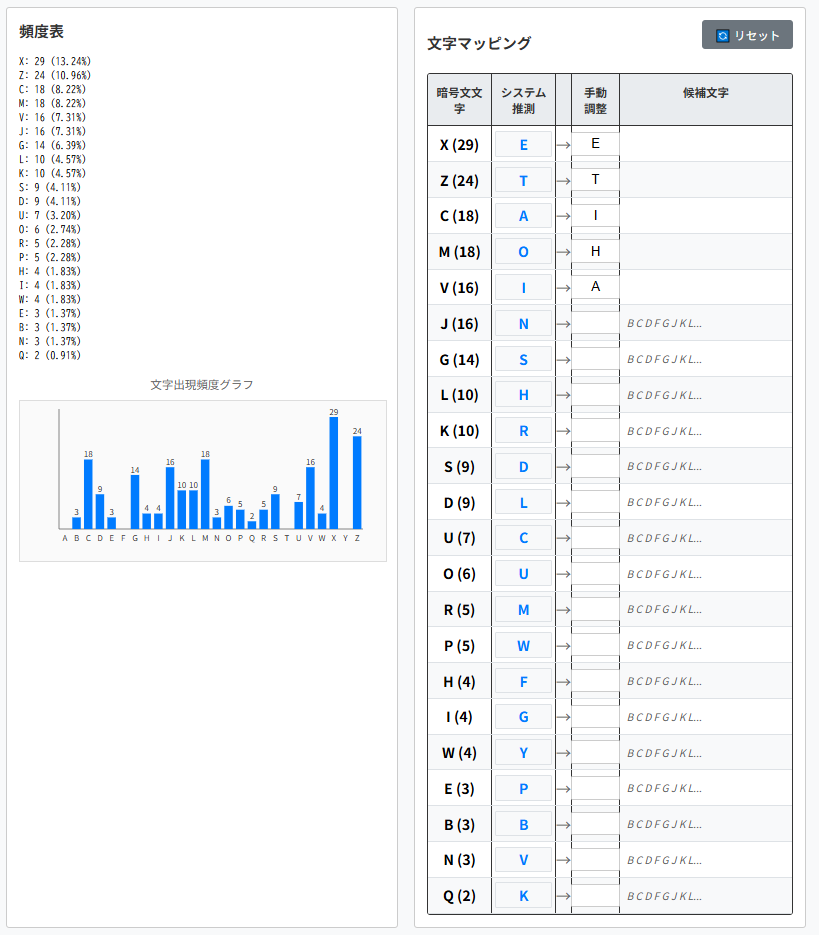
3:ここで一度確定している’t’、’h’、’e’以外をすべて未確定として、解読を進めることにします。
LGGK VHteJ RP VJJCEVO CK the hGEeO C SCLDGEeJeS
LGRe IVIeJL CK the IGDQet GH the SJeLL UhCDh C hVS
tVQeK HJGR PGBJ OVWGJVtGJP. Vt HCJLt C hVS
KeNOeDteS theR, WBt KGU thVt C UVL VWOe tG SeDCIheJ
the DhVJVDteJL CK UhCDh theP UeJe UJCtteK, C
WeNVK tG LtBSP theR UCth SCOCNeKDe.
英語の一文字単語は’I’か’a’のみです。つまり、暗号文文字’C’は、’i’か’a’に対応します。
'C’を含む、別の暗号文単語に注目してください。

単純には確定できません。
そこで、他の単語から調べてみます。
4行目の5文字目の単語"thVt"に注目してください。
“thVt"⇒"that"だと推測できます。
暗号文文字’V’⇒平文文字’a’と仮定すれば、’C’⇒’i’となります(消去法)。
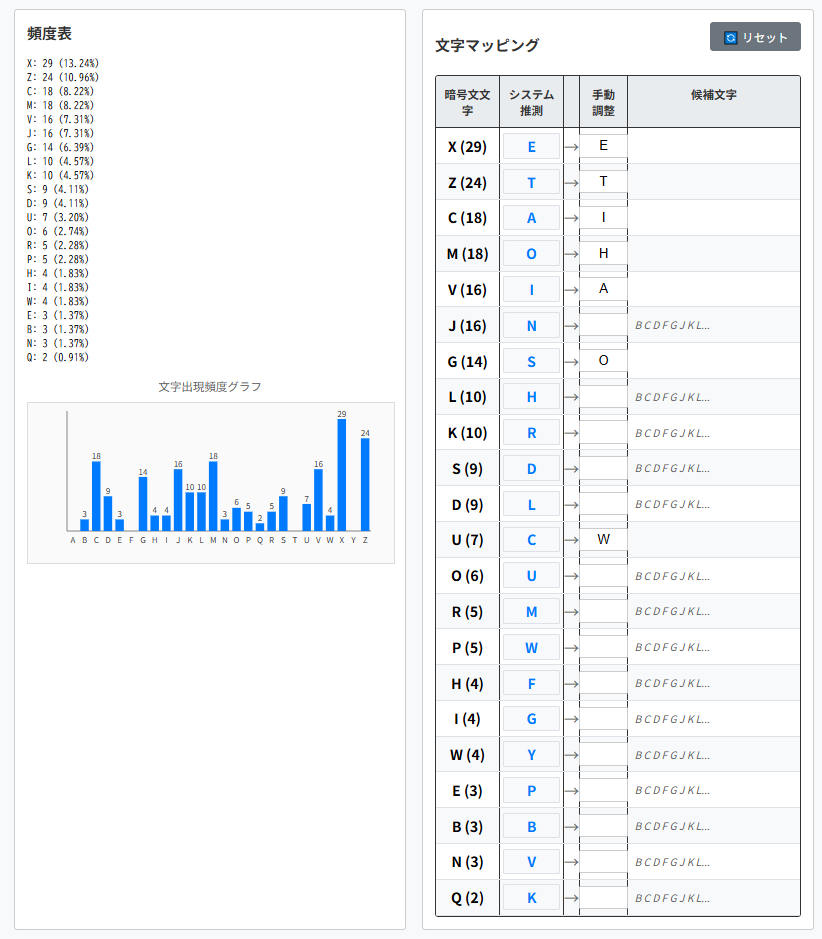
ここまでの結果を文字マッピングに設定します。
LGGK aHteJ RP aJJiEaO iK the hGEeO i SiLDGEeJeS
LGRe IaIeJL iK the IGDQet GH the SJeLL UhiDh i haS
taQeK HJGR PGBJ OaWGJatGJP. at HiJLt i haS
KeNOeDteS theR, WBt KGU that i UaL aWOe tG SeDiIheJ
the DhaJaDteJL iK UhiDh theP UeJe UJitteK, i
WeNaK tG LtBSP theR Uith SiOiNeKDe.
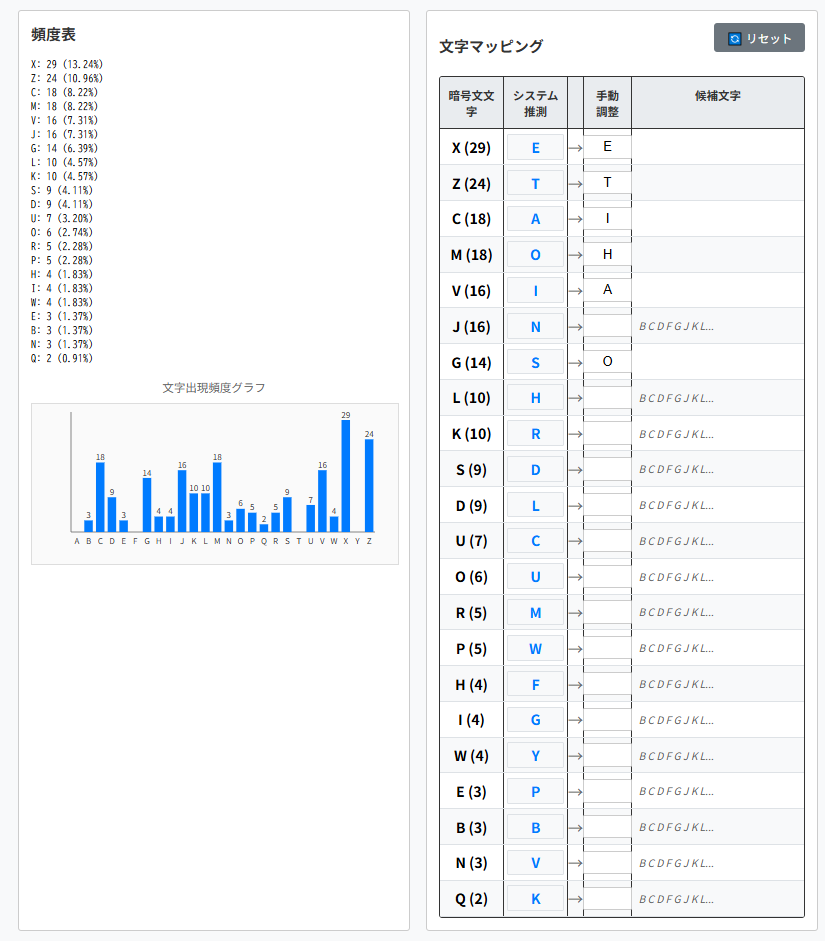
4:最頻文字の’o’の対応がまだ判明していません。
・’J’⇒’o’とすると、1行目が"LGGK aHteo RP aooiEaO iK the hGEeO i SiLDGEeoeS"となり、明らかにおかしい。
・’G’⇒’o’とすると、少し違和感があったとしても、明らかにおかしい部分はない。
・’L’⇒’o’とすると、2行目が"oGRe IaIeJo iK the IGDQet GH the SJeoo UhiDh i haS"となり、明らかにおかしい。
・’K’⇒’o’とすると、4行目が"oeNOeDteS theR, WBt oGU that i UaL aWOe tG SeDiIhe"となり、明らかにおかしい。
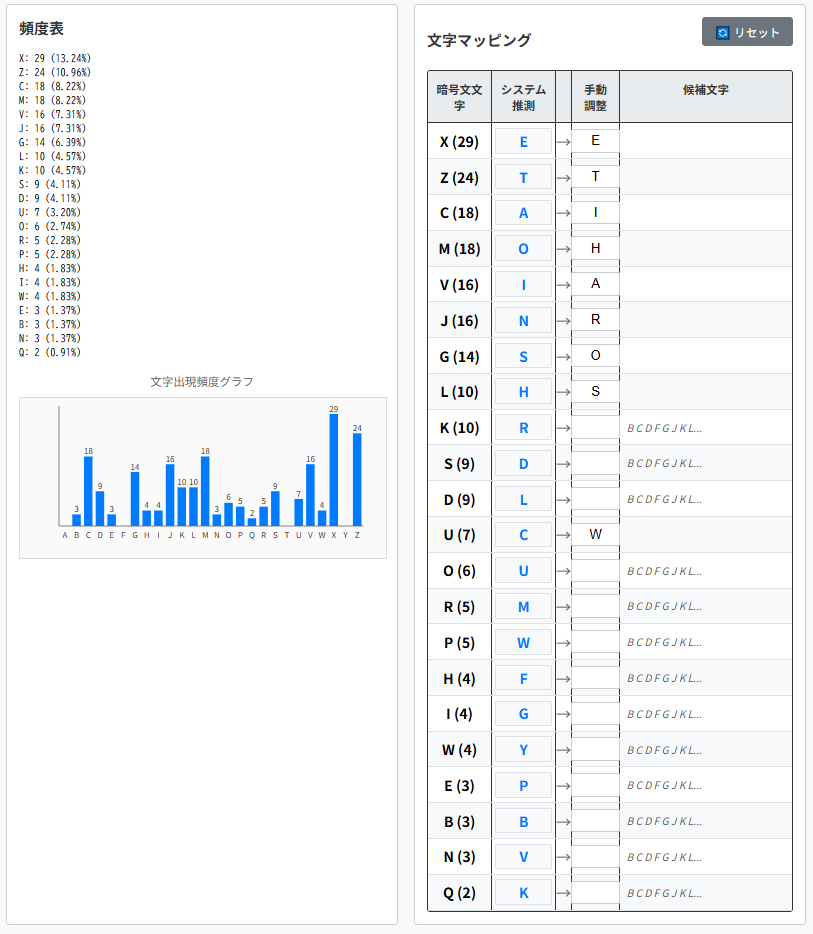
そこで、’G’⇒’o’と仮定します。
LooK aHteJ RP aJJiEaO iK the hoEeO i SiLDoEeJeS
LoRe IaIeJL iK the IoDQet oH the SJeLL UhiDh i haS
taQeK HJoR PoBJ OaWoJatoJP. at HiJLt i haS
KeNOeDteS theR, WBt KoU that i UaL aWOe to SeDiIheJ
the DhaJaDteJL iK UhiDh theP UeJe UJitteK, i
WeNaK to LtBSP theR Uith SiOiNeKDe.
5:6行目の5番目の"Uith"は"with"に対応すると推測できます。
LooK aHteJ RP aJJiEaO iK the hoEeO i SiLDoEeJeS
LoRe IaIeJL iK the IoDQet oH the SJeLL whiDh i haS
taQeK HJoR PoBJ OaWoJatoJP. at HiJLt i haS
KeNOeDteS theR, WBt Kow that i waL aWOe to SeDiIheJ
the DhaJaDteJL iK whiDh theP weJe wJitteK, i
WeNaK to LtBSP theR with SiOiNeKDe.
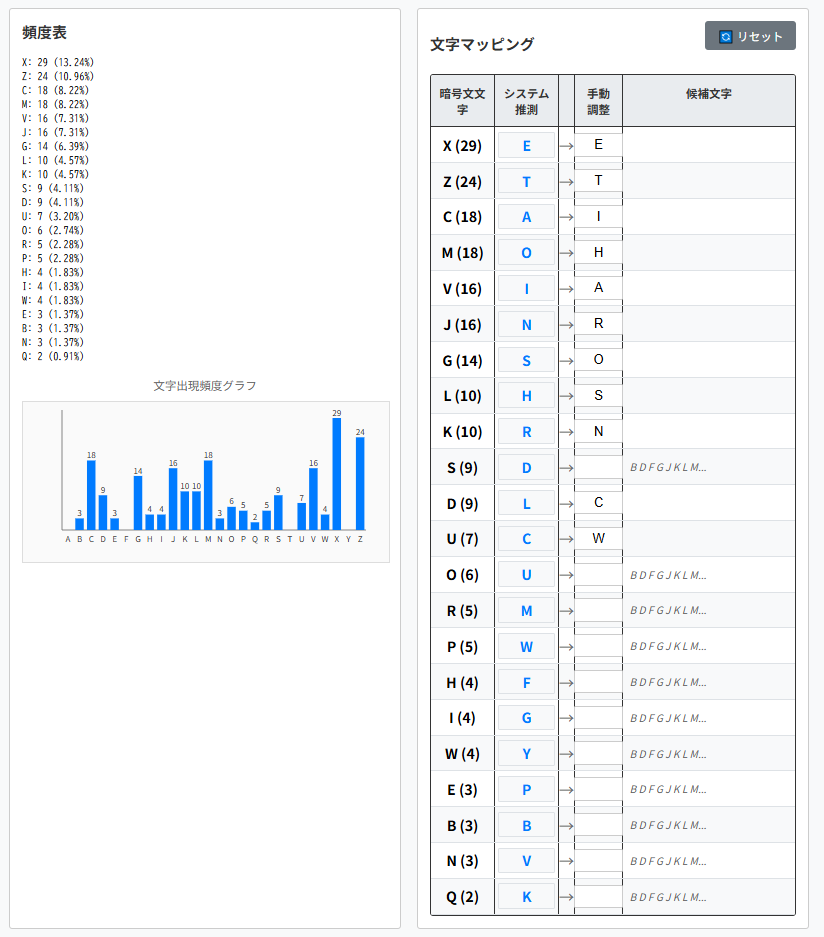
6:わかりやすい単語を探します。
・4行目の7番目の"waL"は、"was"と推測。
・5行目の6番目の"weJe"は、"were"と推測。
sooK aHter RP arriEaO iK the hoEeO i SisDoEereS
soRe IaIers iK the IoDQet oH the Sress whiDh i haS
taQeK HroR PoBr OaWoratorP. at Hirst i haS
KeNOeDteS theR, WBt Kow that i was aWOe to SeDiIher
the DharaDters iK whiDh theP were writteK, i
WeNaK to stBSP theR with SiOiNeKDe.
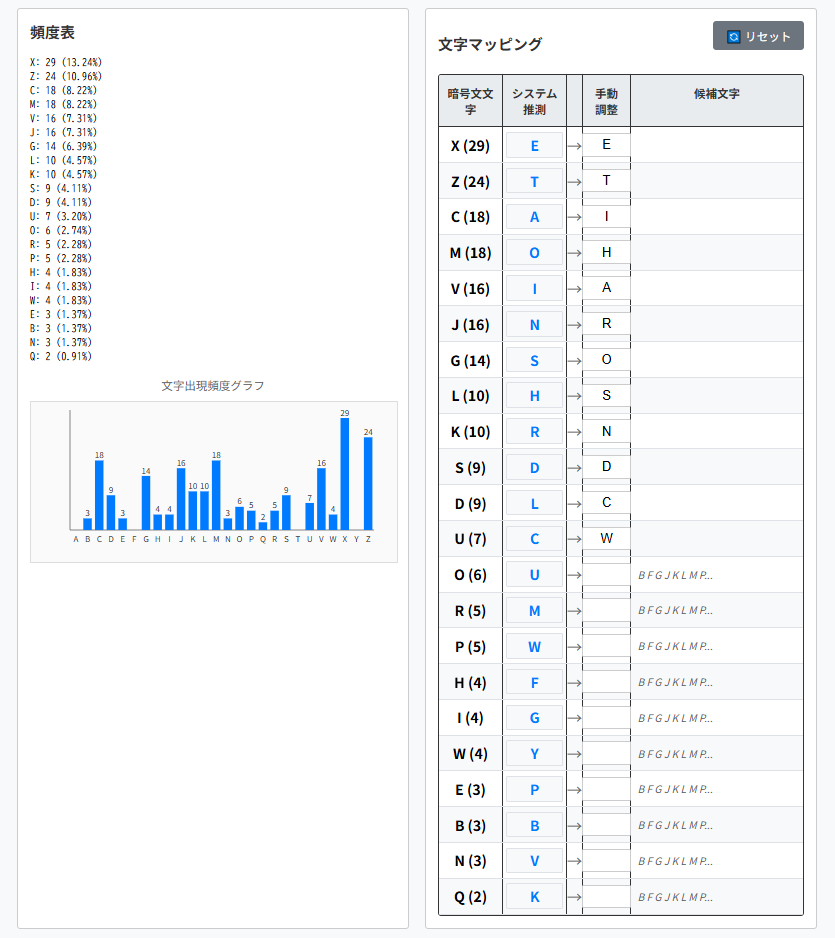
7:新たな単語が見えてきました。
・2行目の9番目の"whiDh"は、"which"と推測。
・5行目の7番目の"writteK"は、"written"と推測。
soon aHter RP arriEaO in the hoEeO i SiscoEereS
soRe IaIers in the IocQet oH the Sress which i haS
taQen HroR PoBr OaWoratorP. at Hirst i haS
neNOecteS theR, WBt now that i was aWOe to SeciIher
the characters in which theP were written, i
WeNan to stBSP theR with SiOiNence.
8:暗号文文字’S’が解読できそうです。

2行目最後の"haS"は、"had"か"has"のどちらかと推測できます。
もし’S’⇒’s’とすると、「"Sress"(2行目、8番目)⇒"sress"」になり、おかしいです。
逆に’S’⇒’d’とすると、「"Sress"⇒"dress"」になり、自然に見えます。
そこで、’S’⇒’d’とします。
soon aHter RP arriEaO in the hoEeO i discoEered
soRe IaIers in the IocQet oH the dress which i had
taQen HroR PoBr OaWoratorP. at Hirst i had
neNOected theR, WBt now that i was aWOe to deciIher
the characters in which theP were written, i
WeNan to stBdP theR with diOiNence.
9:単語の推測を続けられます。
・1行目の2番目の"aHter"は、"after"と推測。
・1行目の最後の"discoEered"は、"discovered"と推測。
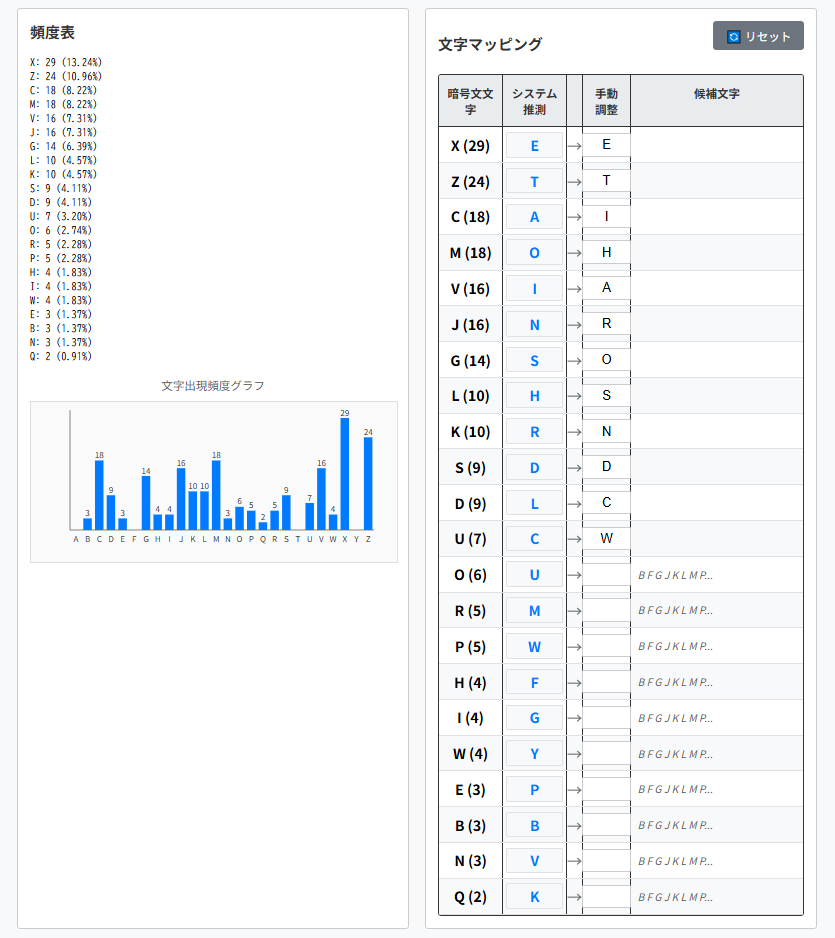
soon after RP arrivaO in the hoveO i discovered
soRe IaIers in the IocQet of the dress which i had
taQen froR PoBr OaWoratorP. at first i had
neNOected theR, WBt now that i was aWOe to deciIher
the characters in which theP were written, i
WeNan to stBdP theR with diOiNence.
10:"theR"(4行目の2番目)や"theP"(5行目の5番目)は、"then"か"them"か"they"と推測できます。ただし’n’は使用済みなので、"them"か"they"になります。
ところで、3行目の2番目に"froR"があります。つまり、’R’⇒’y’ではなく、’R’⇒’m’となります。そして、消去法で’P’⇒’y’になります。
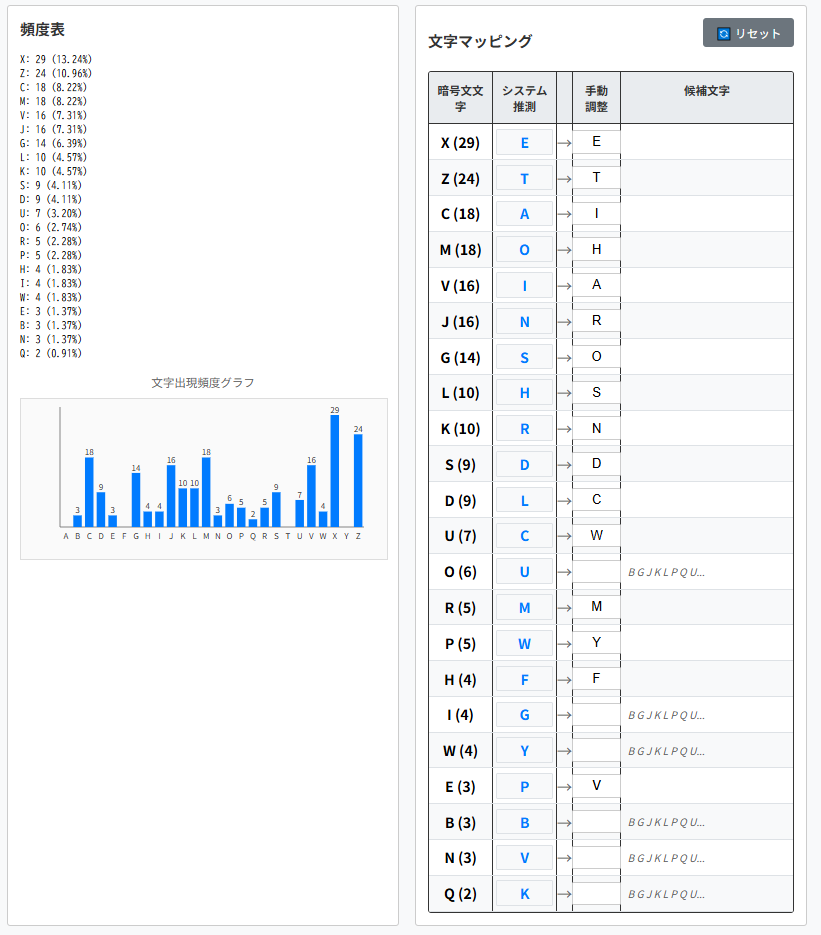
soon after my arrivaO in the hoveO i discovered
some IaIers in the IocQet of the dress which i had
taQen from yoBr OaWoratory. at first i had
neNOected them, WBt now that i was aWOe to deciIher
the characters in which they were written, i
WeNan to stBdy them with diOiNence.
11:単語の推測を進めましょう。
・"arrivaO"(1行目、4番目)⇒"arrival"
・"yoBr"(3行目、3番目)⇒"your"
・"stBdy"(6行目、3番目)⇒"study"
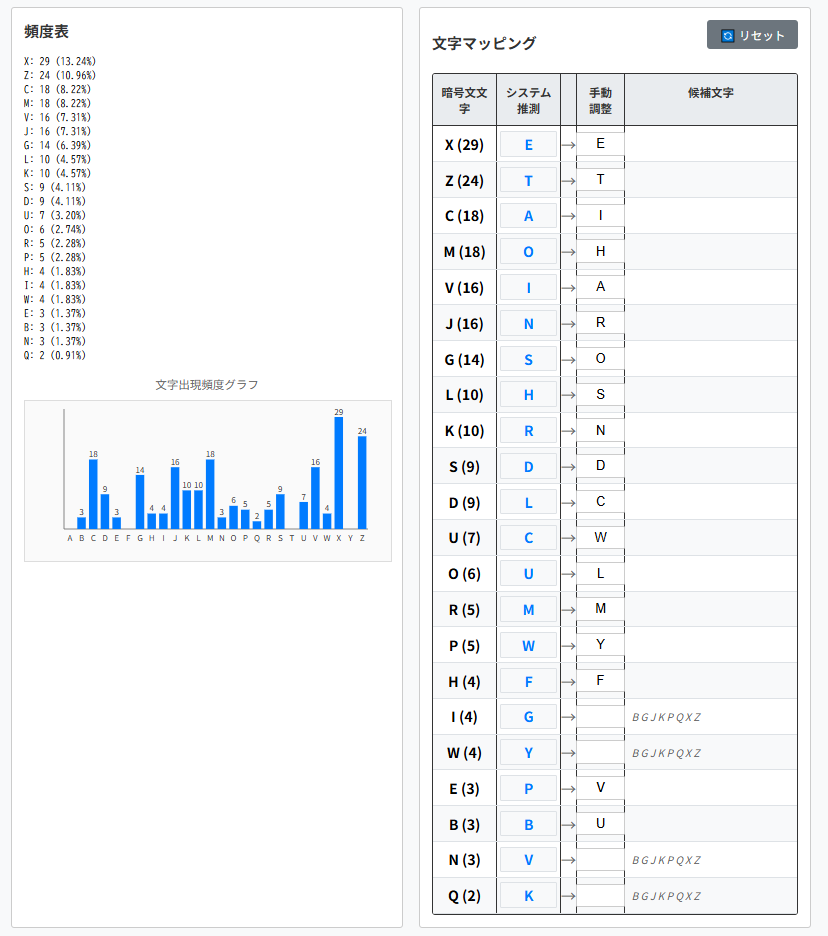
soon after my arrival in the hovel i discovered
some IaIers in the IocQet of the dress which i had
taQen from your laWoratory. at first i had
neNlected them, Wut now that i was aWle to deciIher
the characters in which they were written, i
WeNan to study them with diliNence.
12:4行目の"i was aWle to"に注目してください。
英語の文法的に、’W’⇒’b’と特定できます。
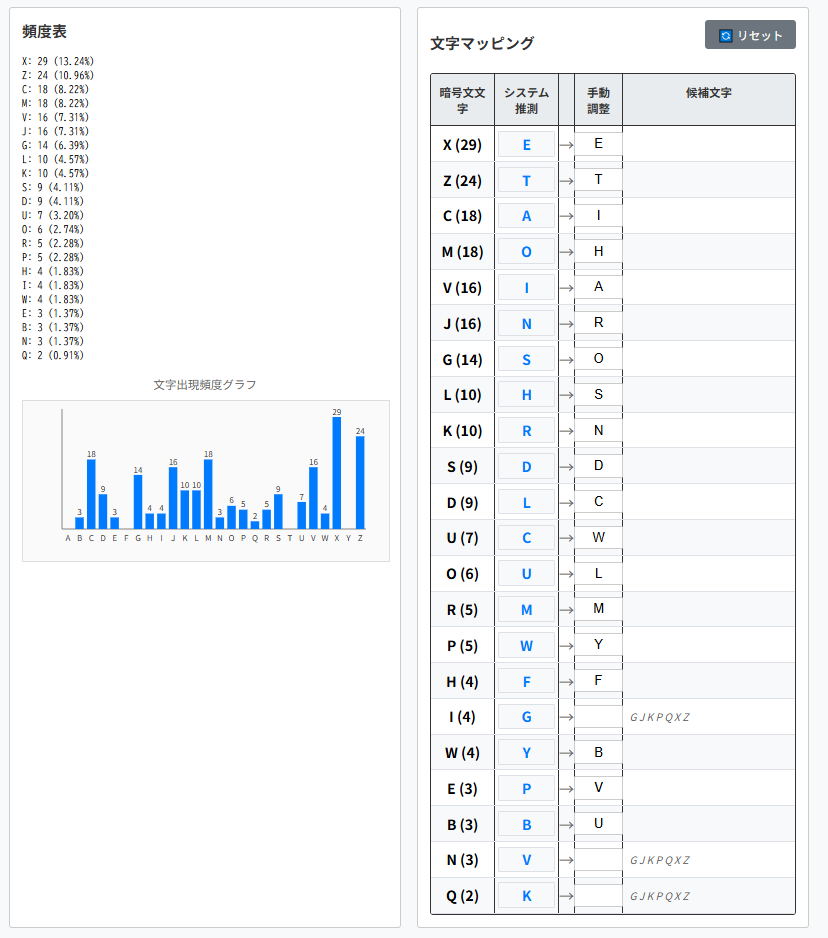
soon after my arrival in the hovel i discovered
some IaIers in the IocQet of the dress which i had
taQen from your laboratory. at first i had
neNlected them, but now that i was able to deciIher
the characters in which they were written, i
beNan to study them with diliNence.
よって、解読キーワードは"laboratory"と判明しました。